How to Handle SQLite Migrations in Durable Objects
🎯 What Problem Are We Trying to Solve?
When you build a real-time app like Preprecords with Durable Objects, you get localized compute — and built-in SQLite storage for each object.
But here’s the tradeoff: each Durable Object is its own tiny database.
That means if your schema evolves, you can’t just run a global migration. You need to handle migrations per object, safely, and without central coordination.
This post goes over a lightweight MigrationsService.
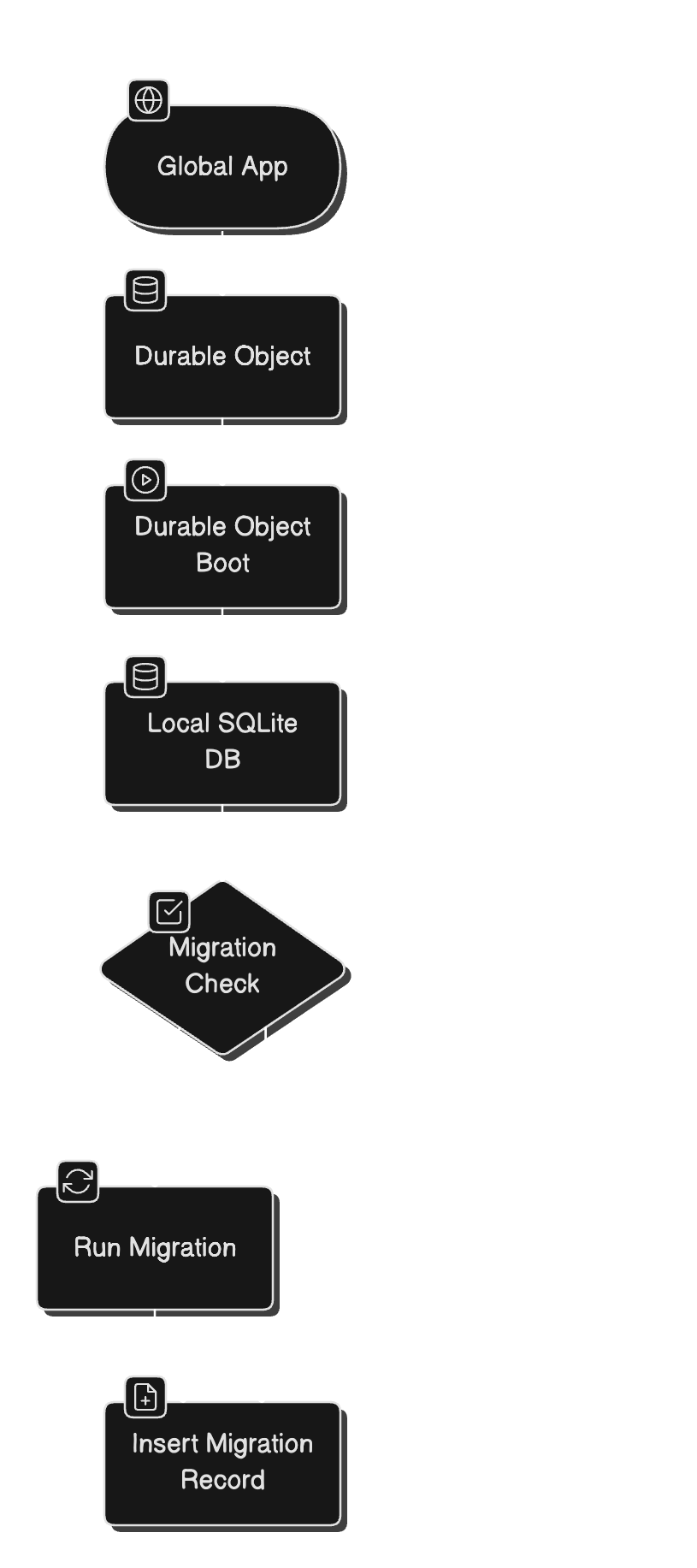
🤔 Why Migrations Matter
Every Durable Object is:
- A singleton
- Scoped by ID (e.g.
user-123,interview-abc) - Has its own local SQLite database
As your app evolves, you’ll want to:
- Add columns to existing tables
- Create new tables
- Add indexes for performance
- Backfill or transform data
And you’ll need to do it safely — even across thousands of active objects.
✅ What We need
We need a solution that:
- Runs only once per object
- Is retry-safe
- Logs which migrations were applied
- Supports SQLite or D1 (
SqlStorage | D1Database) - Feels simple and boring™
✨ Enter MigrationsService

I built a tiny migration system that:
- Runs
upfunctions by name - Tracks them in a
migrationstable - Can be run from inside each Durable Object
Migration interface
export type RunMigration = {
name: string
run: (db: SqlStorage | D1Database) => Promise<void> | void
}Define a migration like this:
const AddArchivedColumn: RunMigration = {
name: '002-add-archived-to-interviews',
run(db) {
db.exec(`ALTER TABLE interviews ADD COLUMN archived INTEGER DEFAULT 0;`)
}
}🛠 Migrations Table
We use Zod to validate migration records:
const MigrationSchema = z.object({
id: z.number(),
name: z.string(),
applied_at: z.number()
})And we create the table:
CREATE TABLE IF NOT EXISTS migrations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT UNIQUE,
applied_at INTEGER NOT NULL DEFAULT (strftime('%s', 'now') * 1000)
);🧠 How It Works
In each Durable Object (e.g. UserInterviews, Interview), we do this on boot:
const migrations = new MigrationsService(this.db)
migrations.runMigrations([
AddInterviewsTable,
AddArchivedColumn,
AddIndexToMessages
])
// durableobjects/interview.ts
class Interview extends Server<Env> {
constructor(ctx: DurableObjectState, env: Env) {
super(ctx, env)
this.interviewAI = new InterviewAI(env)
this.rateLimit = new RateLimit(env)
this.db = new MessagesDB(ctx.storage.sql)
this.ctx.blockConcurrencyWhile(() => {
const migrations = new MigrationsService(this.db)
this.ctx.storage.transactionSync(() => {
migrations.runMigrations([
AddInterviewsTable,
AddArchivedColumn,
AddIndexToMessages
])
})
})
}
This runs migrations that haven’t been applied yet, and skips the rest. Behind the scenes:
if (appliedMigrations.has(migration.name)) {
// ✅ Already applied
continue
}
migration.run(this.db)
this.db.exec(`INSERT INTO migrations (name) VALUES (?)`, migration.name)Great spot to talk about blockConcurrencyWhile — it’s an important but often overlooked part of Durable Object lifecycle. Here’s a concise, developer-friendly explanation you can drop into your migration blog post (or LinkedIn if you want):
🛑 Why We Use blockConcurrencyWhile
In Durable Objects, incoming requests can start processing before the constructor finishes — which means migrations (or setup logic) might still be running when your API is already being hit.
To avoid race conditions, we wrap our migrations in:
this.ctx.blockConcurrencyWhile(() => {
// run migrations
})This tells the DO to pause all incoming requests until the promise resolves.
In our case, it ensures:
- The SQLite schema is ready
- All required tables/columns are in place
- No
.exec()calls hit a missing table
🔴 Why We Use transactionSync
By running runMigrations() inside transactionSync(), we make the entire migration batch atomic — either all migrations apply, or none do.
If a migration fails midway, none of the schema changes are persisted — and the migrations table doesn’t get an inconsistent state.
🔁 Retry-Safe by Design
- You can call
runMigrations()every time the object starts. - It will only apply what’s needed.
- Errors are caught, logged, and bubble up cleanly.
- And with transactionSync(), partial migrations won’t corrupt your database — any failure rolls back the entire batch.
try {
migration.run(db)
db.exec(INSERT_MIGRATION_SQL, name)
} catch (err) {
console.error('Migration failed', name, err)
throw err
}🔄 For Archived or Rehydrated DOs
If you offload old interview data to R2 and later rehydrate it, just re-run migrations before restoring:
const db = new MessagesDB(ctx.storage.sql)
const migrations = new MigrationsService(db)
migrations.runMigrations(MyAppMigrations)📚 Full Code
// services/migrationService.ts
export class MigrationsService {
constructor(private db: SqlStorage) {}
runMigrations(migrations: RunMigration[]) {
this.db.exec(MigrationsService.Queries.CREATE_MIGRATIONS_TABLE)
const applied = new Set(this.getAppliedMigrations().map((m) => m.name))
for (const migration of migrations) {
if (applied.has(migration.name)) {
continue
}
try {
migration.run(this.db)
this.db.exec(MigrationsService.Queries.INSERT_MIGRATION, migration.name)
} catch (error) {
console.error('Migration failed', migration.name, error)
throw error
}
}
}
getAppliedMigrations() {
const rows = this.db.exec(MigrationsService.Queries.GET_ALL).toArray()
return rows.map(this.parseMigrationRow)
}
private parseMigrationRow(row: Record<string, SqlStorageValue>) {
const parsed = MigrationSchema.parse(row)
return {
id: parsed.id,
name: parsed.name,
appliedAt: parsed.applied_at
}
}
private static Queries = {
CREATE_MIGRATIONS_TABLE: `
CREATE TABLE IF NOT EXISTS migrations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT UNIQUE,
applied_at INTEGER NOT NULL DEFAULT (strftime('%s', 'now') * 1000)
);`,
GET_ALL: 'SELECT * FROM migrations;',
INSERT_MIGRATION: `INSERT INTO migrations (name) VALUES (?);`
}
}
// services/MessagesDB.ts
export class MessagesDB {
private readonly sql: SqlStorage
private readonly migrationService: MigrationsService
constructor(sql: SqlStorage) {
this.sql = sql
this.migrationService = new MigrationsService(this.sql)
}
initializeDB() {
try {
this.migrationService.runMigrations(MIGRATIONS)
} catch (error: unknown) {
const message =
error instanceof Error ? error.message : 'An error occurred'
throw new DBError(
`Failed to run migrations: ${message}`,
ErrorCodes.DB_ERROR
)
}
}
//...
}
// durableObjects/Interview.ts
export class Interview extends Server<Env> {
constructor(ctx: DurableObjectState, env: Env) {
super(ctx, env)
this.interviewAI = new InterviewAI(env)
this.rateLimit = new RateLimit(env)
this.db = new MessagesDB(ctx.storage.sql)
this.ctx.blockConcurrencyWhile(() => this.init())
}
async init() {
this.ctx.storage.transactionSync(() => this.db.initializeDB())
}
//....
}
🚀 Where We Use This in Preprecords
UserInterviewsDurable Object →interviews.sqliteInterviewDurable Object →messages.sqlite
Each one calls runMigrations() when it spins up.
We also use this pattern to prepare fresh DOs when rehydrating from R2, or running scheduled migrations via alarms.
🧵 Related Reading
If you haven’t read the first part in this series yet:
👉 How I Built a Real-Time AI App with Cloudflare Durable Objects and Workers AI
It covers:
- Streaming AI with Workers AI
- Per-user DOs with SQLite
- Resilient WebSockets with Partykit
- Rate limiting, state machines, and more
💡 Thoughts on Scaling
Each Durable Object (like UserInterviews or Interview) manages its own SQLite database — great for isolation and performance.
But we still need a global view of interviews across the system — for things like:
- Running batch migrations
- Performing analytics
- Rehydrating archived interviews from R2
- Triggering cross-object workflows
To solve this, we mirror interview metadata into a central Cloudflare D1 database whenever an interview is created:
// durableObjects/UserInterviews.ts
export class UserInterviews extends Server<Env> {
private readonly db: InterviewDB
private readonly globalDB: GlobalDB
constructor(ctx: DurableObjectState, env: Env) {
super(ctx, env)
this.db = new InterviewDB(ctx.storage.sql)
this.globalDB = new GlobalDB(env.DB)
}
async createInterview(interview: CreateInterview): Promise<InterviewT> {
const createdInterview = this.db.createInterview(interview)
// Broadcast via WebSocket
this.broadcast(wsInterviewCreatedMessage(createdInterview))
// 🔁 Store in global D1 table
await this.globalDB.createInterview(createdInterview)
return createdInterview
}This gives us:
- A single table of all interviews, regardless of which Durable Object they live in
- The ability to run scripts or Workers that:
- Query interviews from D1
- make RPC calls on the appropriate Durable Object ID
- Apply schema changes, upgrades, or even rehydration logic
It’s a lightweight pattern that keeps each DO self-contained while enabling global coordination.

🧠 Conclusion
Handling SQLite migrations in Durable Objects doesn’t need to be complicated.
With a tiny MigrationsService, you can:
- Run migrations safely on every boot
- Keep every object schema up-to-date
- Support evolving features as your app grows
It’s boring. It’s predictable. It works at the edge.